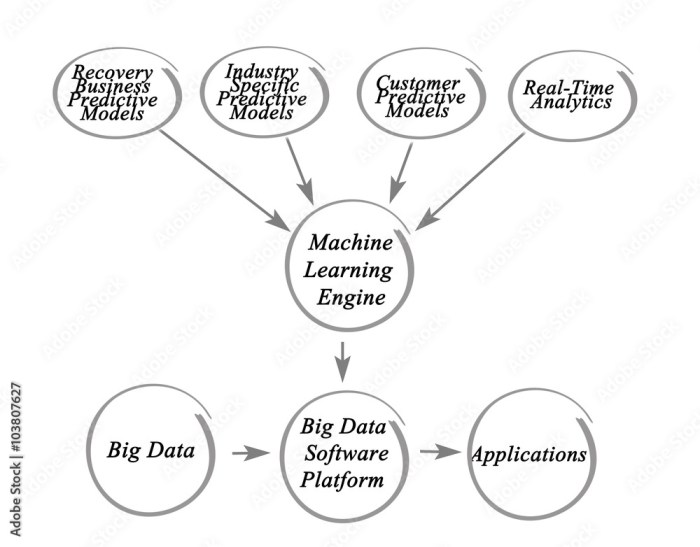
big data processing is revolutionizing how organizations harness vast amounts of information in today’s data-driven world. Companies across various industries are increasingly relying on sophisticated techniques to process, analyze, and derive meaningful insights from colossal datasets. This not only enhances decision-making but also drives innovation and efficiency. However, as the volume, variety, and velocity of data continue to grow, businesses face significant challenges in managing and processing these large datasets effectively.
Understanding big data processing involves exploring the types of data involved, the technologies enabling processing, and the diverse applications that stem from it. From traditional SQL models to modern NoSQL databases, the landscape of data storage solutions is continually evolving, making it crucial for organizations to stay informed and adapt to best practices in data management.
Introduction to Big Data Processing
Big data processing refers to the methods and technologies employed to handle vast volumes of structured and unstructured data that exceed the capabilities of traditional data processing applications. In today’s digital landscape, where data generation occurs at an unprecedented scale, the significance of big data processing cannot be overstated. Organizations leverage big data analytics to derive actionable insights, drive business decisions, and enhance customer experiences.
The types of data involved in big data processing include structured data, such as databases and spreadsheets; semi-structured data, like XML and JSON files; and unstructured data, which encompasses text, images, videos, and social media content. Managing these diverse data types poses numerous challenges, including data quality issues, data integration complexities, and the need for real-time processing capabilities.
Key Technologies in Big Data Processing
To effectively process big data, organizations employ a variety of advanced technologies. Among the most popular frameworks are Apache Hadoop and Apache Spark. Hadoop provides a distributed storage and processing solution that allows for the handling of large datasets across clusters of computers. Spark, on the other hand, allows for fast data processing with its in-memory computing capabilities, making it ideal for iterative algorithms and real-time data processing.
Distributed computing plays a crucial role in big data processing by enabling the division of large datasets across multiple servers, thus improving performance and scalability. This approach not only enhances the speed of data processing but also provides fault tolerance, ensuring that tasks can continue even if individual nodes fail.
Cloud computing is also pivotal in managing big data. Cloud platforms offer scalable storage and computing resources that can accommodate the fluctuating workloads associated with big data processing. Organizations can leverage cloud-based solutions for cost efficiency, flexibility, and easy access to advanced analytics tools.
Data Storage Solutions

When considering data storage options for big data, there are notable differences between NoSQL databases and traditional SQL databases. NoSQL databases, such as MongoDB and Cassandra, are designed to handle large volumes of unstructured data and provide high scalability and performance. In contrast, SQL databases excel in structured data management but may struggle with the scalability required for big data applications.
Distributed file systems, like Hadoop Distributed File System (HDFS), provide a robust solution for storing large datasets across multiple nodes. HDFS is designed for fault tolerance and high throughput, making it suitable for big data applications.
Ensuring data durability and accessibility in big data environments can be achieved through various methods, including data replication, partitioning, and backup strategies. These practices safeguard data integrity and ensure that critical information remains available even in the event of system failures.
Data Processing Techniques, Big data processing
Batch processing is a prevalent technique used in big data to handle large volumes of data over a defined period. It is particularly useful for processing historical data and performing complex calculations. Use cases for batch processing include data warehousing and ETL (Extract, Transform, Load) operations.
Real-time processing, in contrast, enables organizations to analyze data as it is generated. Technologies such as Apache Kafka and Apache Flink facilitate real-time data ingestion and processing, allowing businesses to respond swiftly to changes in data streams. This capability is vital for applications such as fraud detection and real-time analytics.
Stream processing architectures, like the Lambda architecture, combine batch processing and real-time processing to provide a comprehensive view of data. These architectures enable organizations to handle both historical and live data efficiently.
Data Analysis and Visualization

Data analytics plays a pivotal role in big data processing, transforming raw data into meaningful insights. Techniques such as machine learning, statistical analysis, and data mining are employed to extract valuable information from large datasets.
Effective visualization of large datasets is crucial for conveying insights clearly and concisely. Tools such as Tableau, Power BI, and D3.js facilitate the creation of intuitive visual representations, enabling stakeholders to grasp complex data trends and patterns.
Software solutions that support data analysis and visualization not only enhance decision-making but also improve collaborative efforts across teams. By providing access to real-time data visualizations, organizations can foster a data-driven culture that encourages informed decision-making.
Use Cases of Big Data Processing
Various industries leverage big data processing to gain competitive advantages and improve operational efficiency. In healthcare, organizations utilize big data to enhance patient care through predictive analytics and personalized medicine. The finance sector employs big data analytics for risk management and fraud detection, while the retail industry uses it to personalize customer experiences and optimize supply chain operations.
Specific case studies highlight successful big data implementations. For instance, a leading healthcare provider utilized big data analytics to reduce patient readmission rates by analyzing historical data and identifying high-risk patients. Similarly, a major retail chain used real-time analytics to adjust inventory levels based on customer purchasing patterns, resulting in increased sales.
Emerging trends in big data applications include the integration of artificial intelligence (AI) and machine learning to automate data analysis processes, driving further innovation and efficiency across sectors.
Best Practices for Big Data Management

Ensuring data quality in big data processing is paramount. Organizations should implement strategies such as data cleansing and validation to maintain high data standards. Regular audits and monitoring can help identify and rectify data quality issues proactively.
Data governance and compliance are essential components of big data management. Establishing clear policies and guidelines ensures that data is handled responsibly and in accordance with regulatory requirements. This includes securing sensitive information and adhering to data privacy regulations.
Effective organizational practices for big data management encompass cross-functional collaboration, data stewardship, and continuous training. By fostering a culture of accountability and knowledge-sharing, organizations can optimize their big data initiatives and unlock the full potential of their data assets.
Future of Big Data Processing
The future of big data processing is poised for significant advancements, with emerging technologies such as quantum computing and advanced AI algorithms set to transform data processing capabilities. These advancements promise to enhance the speed and efficiency of data analytics, allowing organizations to glean insights from even larger datasets.
However, as technology evolves, new challenges may arise in the realm of big data processing. Issues such as data security, privacy concerns, and the need for transparent algorithms will require ongoing attention and innovative solutions.
AI and machine learning will play a crucial role in shaping the future of big data. By automating data processing tasks and enhancing predictive analytics, these technologies will enable organizations to make more informed decisions and respond dynamically to changing market conditions.
Ultimate Conclusion: Big Data Processing
As we look toward the future of big data processing, advancements in technology promise to address existing challenges while opening new avenues for innovation. The integration of AI and machine learning is set to redefine how we interpret and utilize data, enhancing the speed and accuracy of insights. By adhering to best practices and embracing emerging trends, organizations can not only succeed in their current efforts but also thrive in the ever-evolving data landscape.